defmain(args: Array[String]): Unit = { val builder: SparkSession.Builder = SparkSession.builder().master("local[*]") val spark: SparkSession = builder.appName("subjectThree") .enableHiveSupport() .getOrCreate() import spark.sql
val sdf = newSimpleDateFormat("yyyyMMdd") val calendar: Calendar = Calendar.getInstance calendar.add(Calendar.DATE,0) val date: Date = calendar.getTime val dateStr: String = sdf.format(date)
// 对于dwd层 //新版spark对于数据格式转换有强制要求,可采取旧版的 spark.sql(" set spark.sql.storeAssignmentPolicy=LEGACY")
sql( """ |with a as ( --获取orders表 需要的信息 作为表a |select cust_key, | total_price, | date_format(TO_DATE(order_date), 'yyyy') as year, | date_format(TO_DATE(order_date), 'MM') as month, | date_format(TO_DATE(order_date), 'dd') as day |from dwd.fact_orders), |b as ( -- 每人每天的信息 | select fo.cust_key as keys, | max(name) as name, | a.year,a.month,a.day | from dwd.fact_orders fo | left join dwd.dim_customer cust on cust.cust_key=fo.cust_key | left join a on a.cust_key=fo.cust_key | group by fo.cust_key,year,month,day), |c as ( -- 每月的订单数 和 金额 | select sum(total_price) as totalconsumption, | count(1) as totalorder, | year,month | from a | group by year,month) |select keys,name, | totalconsumption, | totalorder, | b.year,b.month,b.day |from b |left join c on b.month=c.month |order by keys |""".stripMargin).coalesce(50).createOrReplaceTempView("my_aggr") sql( """ |insert overwrite table dws.customer_consumption_day_aggr |select * from my_aggr |""".stripMargin) spark.stop() } }
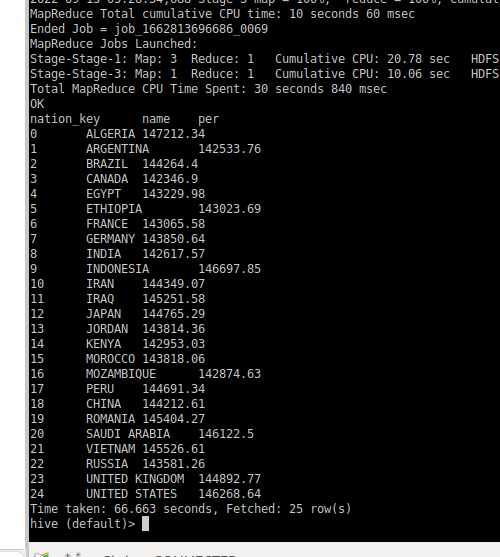
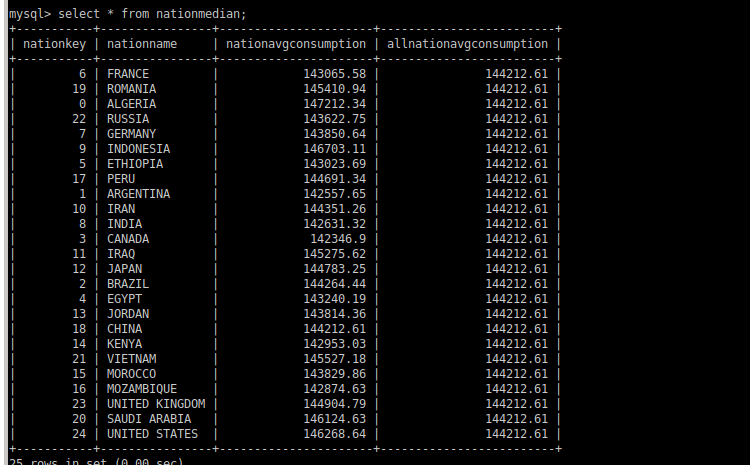
//计算出某年每个国家的平均消费额和所有国家平均消费额相比较结果 sql( """ |-- a 获得每个消费人的总消费额 以及信息 |with a as (select fo.cust_key, |max(nation.nation_key) as nation_key, |max(nation.name) as name , |sum(total_price) as total_price from fact_orders fo |left join dim_customer cust on cust.cust_key=fo.cust_key |left join dim_nation nation on cust.nation_key=nation.nation_key |group by fo.cust_key), |--b 每个国家 人均消费 |b as (select nation_key as nationkey ,max(name) as name ,sum(total_price) as sumprice,count(1) as countperson, |round(avg(total_price),2) as avgnationperson |from a group by nation_key) |select nationkey,name,round(avgnationperson,2),306980.73,( |case when avgnationperson > 306980.73 then '+' | when avgnationperson = 306980.73 then '=' | when avgnationperson < 306980.73 then '-' end) |from b |""".stripMargin).coalesce(50).createOrReplaceTempView("my_nation_avg")
4. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
很久没写sql逻辑语句了
case 这里出现了BUG BUG在另一台机器上 图片就不列出来了
出现问题的原因是case最后忘记加了end when之间是不需要加,的 之前也因为这个报错过
如果是判断是否为一个值或者一个字符等 case 属性 when 条件 这样的方式去做
1 2 3
case when avgnationperson > 306980.73 then '+' when avgnationperson = 306980.73 then '=' when avgnationperson < 306980.73 then '-' end)
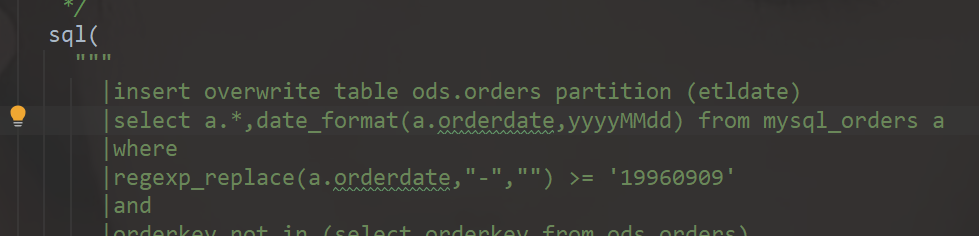
/** * 要求只取某年某月某日及之后的数据(包括某年某月某日) * ,根据ORDERS表中ORDERKEY作为增量字段(提示:对比MySQL和Hive中的表的ORDERKEY大小), * 只将新增的数据抽入,字段类型不变,同时添加动态分区,分区字段类型为String, * 且值为ORDERDATE字段的内容(ORDERDATE的格式为yyyy-MM-dd,分区字段格式为yyyyMMdd) */ sql( """ |insert overwrite table ods.orders partition (etldate) |select a.*,date_format(orderdate,'yyyyMMdd') from mysql_orders a |where |regexp_replace(a.orderdate,"-","") >= '19960909' |and |orderkey not in (select orderkey from ods.orders) |""".stripMargin)
sql("truncate table ods.lineitem")
/** * 根据LINEITEM表中orderkey作为增量字段,只将新增的数据抽入 */ sql( """ |insert overwrite table ods.lineitem partition (etldate='20220906') |select * from mysql_lineitem |where orderkey not in (select orderkey from ods.lineitem) |""".stripMargin)
//创建连接mysql表格函数 --连接 参数 //1.SparkSession提供连接 dbtable 连接到的表格 temporaryName创建临时表的名字 defConnectMysql(spark:SparkSession,dbtable:String,temporaryName:String):Unit ={ valURL="jdbc:mysql://192.168.23.89:3306/shtd_store" val driver="com.mysql.jdbc.Driver" val user="root" val password="123456" spark.read.format("jdbc") .option("url",URL) . option("driver",driver) .option("user",user) .option("password",password) .option("dbtable",dbtable).load().createTempView(temporaryName) } } }
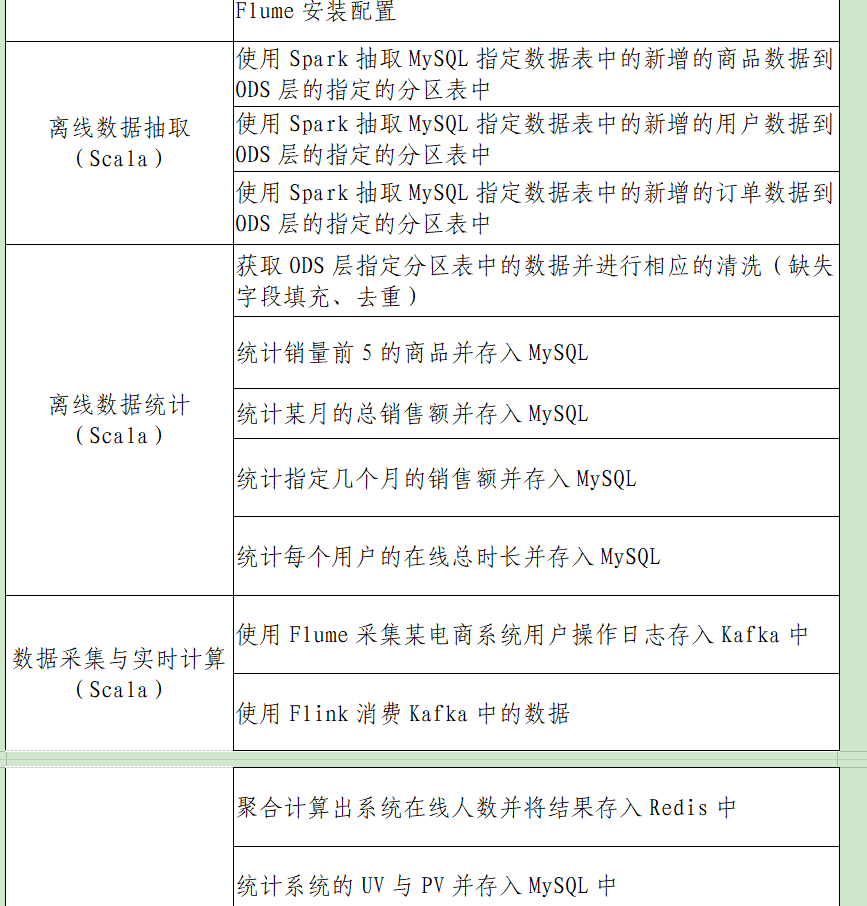
给可视化接口提供sql文件
查询\1. 表二:以订单表为主表, 显示各订单主要信息如下 :
地区, 国家, 客户名, 采购订单消费额, 供应商名称, 时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
select region.name as region_name, nation.name as nation_name, cust.name as cust_name, --销售额 t1.sumprice, supplier.name as supplier_name, fo.order_date from dwd.fact_orders fo leftjoin dwd.dim_customer cust on cust.cust_key=fo.cust_key leftjoin dwd.dim_nation nation on cust.nation_key=nation.nation_key leftjoin dwd.dim_region region on nation.region_key=region.region_key join dwd.fact_lineitem lineitem on lineitem.order_key=fo.order_key leftjoin ods.supplier supplier on supplier.suppkey=lineitem.supp_key join--总订单额 (select cust2.cust_key,sum(total_price) as sumprice from dwd.fact_orders fo2 leftjoin dwd.dim_customer cust2 on cust2.cust_key= fo2.cust_key groupby cust2.cust_key) t1 on t1.cust_key=fo.cust_key
//增量抽取的两条 //orders 取19970802以后的 动态分区 spark.sql( """ |insert overwrite table ods.orders partition (etldate) |select o.*, |date_format(orderdate,'yyyyMMdd') |from mysql_orders o |where regexp_replace(o.orderdate,"-","") >= '19970802' |and |orderkey not in |(select orderkey from ods.orders) |""".stripMargin)
// //orderkey 增量字段 静态分区 spark.sql( s""" |insert overwrite table ods.lineitem partition (etldate=$date) |select * from mysql_lineitem |where orderkey not in |(select orderkey from ods.lineitem) |""".stripMargin)
defhiveT6(spark: SparkSession,hiveName:String): Unit ={ spark.sql( s""" |insert overwrite table ods.$hiveName partition (etldate=$date) |select * from mysql_$hiveName |""".stripMargin) } deflocalMysqlByMyself(Spark:SparkSession,mysqlName:String,tempName:String): Unit ={ val url="jdbc:mysql://192.168.23.89:3306/shtd_store" val driver="com.mysql.jdbc.Driver" val user="root" val password="123456"
objectDataMath2{ defmain(args: Array[String]): Unit = { val builder: SparkSession.Builder = SparkSession.builder().master("local[*]") val spark: SparkSession = builder.appName("DataChouQu2").enableHiveSupport() .config("hive.exec.dynamic.partition", "true") .config("hive.exec.dynamic.partition.mode", "nonstrict") .config("hive.exec.max.dynamic.partitions", "100000") .config("hive.exec.max.dynamic.partitions.pernode", "100000") .getOrCreate() import spark.sql loadMysql(spark,"nationeverymonth","mysql1") loadMysql(spark,"nationavgcmp","mysql2")
sql("truncate table dws.customer_consumption_day_aggr") sql( """ |with t1 as ( |select fo.cust_key as cust_key, |cust.name as name, |total_price, |date_format(to_date(order_date),'yyyy') as year, |date_format(to_date(order_date),'MM') as month, |date_format(to_date(order_date),'dd') as day |from dwd.fact_orders fo |left join dwd.dim_customer cust on cust.cust_key=fo.cust_key) |select cust_key,max(name),sum(total_price),count(1),year,month,day |from t1 |group by t1.cust_key,name,year,month,day |""".stripMargin).coalesce(50).createTempView("sub1") sql( """ |insert overwrite table dws.customer_consumption_day_aggr |select * from sub1 |""".stripMargin)
sql( """ |with t1 as ( |select cust_key, |sum(totalconsumption) as sumprice, |count(1) as countprice, |year,month from dws.customer_consumption_day_aggr |group by cust_key,year,month), |t2 as ( |select |ccda.cust_key, |ccda.cust_name, |nation.nation_key, |nation.name as nation_name, |region.region_key, |region.name as region_name, |t1.sumprice as totalconsumption, |t1.countprice as totalorder, |t1.year,t1.month |from dws.customer_consumption_day_aggr ccda |left join dwd.dim_customer cust on ccda.cust_key=cust.cust_key |left join dwd.dim_nation nation on cust.nation_key=nation.nation_key |left join dwd.dim_region region on nation.region_key=region.region_key |join t1 on t1.cust_key=ccda.cust_key |group by ccda.cust_key, |ccda.cust_name, |nation.nation_key, |nation.name, |region.region_key, |region.name , |t1.sumprice, |t1.countprice, |t1.year,t1.month) |select t2.*,rank() over(partition by t2.cust_key order by totalconsumption,totalorder,month desc) |from t2 |""".stripMargin).coalesce(50).createTempView("sub2")
sql( """ |-- a 获得每个消费人的总消费额 以及信息 |with a as (select fo.cust_key, |max(nation.nation_key) as nation_key, |max(nation.name) as name , |sum(total_price) as total_price from dwd.fact_orders fo |left join dwd.dim_customer cust on cust.cust_key=fo.cust_key |left join dwd.dim_nation nation on cust.nation_key=nation.nation_key |group by fo.cust_key), |--b 每个国家 人均消费 |b as (select nation_key as nationkey ,max(name) as name ,sum(total_price) as sumprice,count(1) as countperson, |round(avg(total_price),2) as avgnationperson |from a group by nation_key) |select nationkey,name,round(avgnationperson,2),306980.73,( |case when avgnationperson > 306980.73 then '+' | when avgnationperson = 306980.73 then '=' | when avgnationperson < 306980.73 then '-' end) |from b |""".stripMargin).coalesce(50).createTempView("sub3")
defloadMysql(Spark:SparkSession,totalName:String,tempName:String): Unit ={ val url="jdbc:mysql://192.168.23.89/shtd_store" val user="root" val password="123456" val driver="com.mysql.jdbc.Driver" Spark.read.format("jdbc") .option("url",url) .option("user",user) .option("password",password) .option("driver",driver) .option("dbtable",totalName).load().createTempView(tempName) } } }
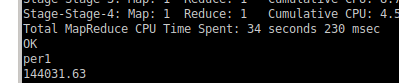
//percentile_approx(col,p) p=0.5 col为中位数的列 求中位数 //percentile_approx第一个参数只能是int //hive (default)> set hive.strict.checks.cartesian.product=true; //hive (default)> set hive.mapred.mode=nonstrict; sql("set hive.strict.checks.cartesian.product=true") //hive开启笛卡尔积支持 sql("set hive.mapred.mode=nonstrict") //开启非严格模式 sql( """ |with t1 as ( |select nation.nation_key as nation_key,max(nation.name) as name , |round(percentile_approx(total_price,0.5),2) as per |from dwd.fact_orders fo |left join dwd.dim_customer cust on cust.cust_key=fo.cust_key |left join dwd.dim_nation nation on nation.nation_key=cust.nation_key |group by nation.nation_key), |t2 as ( |select round(percentile_approx(per,0.5),2) as per1 |from t1 |) |select t1.*,t2.* from t1,t2 |""".stripMargin).coalesce(50).createTempView("hive2") mysqlExtract(spark,"nationmedian","mysql2")
//hive sql 6 hiveExtract(spark,"customer") hiveExtract(spark,"nation") hiveExtract(spark,"part") hiveExtract(spark,"partsupp") hiveExtract(spark,"region") hiveExtract(spark,"supplier") spark.sql( s""" |insert overwrite table ods.lineitem partition (etldate=$date) |select l.* from mysql_lineitem l |where |l.orderkey not in |(select orderkey from ods.lineitem) |""".stripMargin) spark.stop()
defhiveExtract(spark:SparkSession,hiveName:String): Unit ={ spark.sql( s""" |insert overwrite table ods.$hiveName partition (etldate=$date) |select * from mysql_$hiveName |""".stripMargin) }
defmysqlExtract(spark:SparkSession,mysqlName:String,tempName:String): Unit ={ val url="jdbc:mysql://192.168.23.89/shtd_store" val driver="com.mysql.jdbc.Driver" val user="root" val password="123456" spark.read.format("jdbc") .option("url",url) .option("driver",driver) .option("user",user) .option("password",password) .option("dbtable",mysqlName).load().createTempView(tempName) } } }
spark.sql( """ |WITH t1 as ( |select c.cust_key as custkey, |n.nation_key as nationkey, |n.name as nationname, |r.region_key as regionkey, |r.name as regionname, |total_price, |date_format(order_date,'yyyy') as year, |date_format(order_date,'MM') as month |from dwd.fact_orders fo |left join dwd.dim_customer c on fo.cust_key=c.cust_key |left join dwd.dim_nation n on c.nation_key=n.nation_key |left join dwd.dim_region r on n.region_key=r.region_key) |select nationkey,max(nationname),max(regionkey),max(regionname), |sum(total_price),count(*),year,month |from t1 |group by nationkey,year,month |""".stripMargin).coalesce(50).createTempView("hive1") mysqlExtract(spark,"nationeverymonth","mysql1") spark.sql( """ |insert overwrite table mysql1 |select * from hive1 |""".stripMargin)
defmysqlExtract(spark: SparkSession, mysqlName: String, tempName: String): Unit = { val url = "jdbc:mysql://192.168.23.89/shtd_store" val driver = "com.mysql.jdbc.Driver" val user = "root" val password = "123456" spark.read.format("jdbc") .option("url", url) .option("driver", driver) .option("user", user) .option("password", password) .option("dbtable", mysqlName).load().createTempView(tempName) } } }
/* hive (default)> set hive.strict.checks.cartesian.product=true; hive (default)> set hive.mapred.mode=nonstrict; */ sql("set hive.strict.checks.cartesian.product=true") sql("set hive.mapred.mode=nonstrict") sql( """ |with t1 as ( |select c.cust_key as custkey, |n.nation_key as nationkey, |n.name as nationname, |total_price |from dwd.fact_orders fo |left join dwd.dim_customer c on fo.cust_key=c.cust_key |left join dwd.dim_nation n on c.nation_key=n.nation_key), |t2 as ( |select custkey,max(nationkey) as nationkey, max(nationname) as nationname, |sum(total_price) as sumprice |from t1 |group by t1.custkey), |t3 as ( |select nationkey, |max(nationname) as nationname, |round(avg(sumprice),2) as avgprice |from t2 |group by nationkey), |t4 as ( |select round(avg(sumprice),2) as allavgprice from t2) |select t3.*,t4.* from t3,t4 |""".stripMargin).coalesce(50).createTempView("hive4")
mysqlExtract(spark,"nationavgcmp","nationavgcmp") spark.conf.set("spark.sql.crossJoin.enabled","true") sql( """ |insert overwrite table nationavgcmp |select h.*, |(case |when h.avgprice > h.allavgprice then '+' |when h.avgprice = h.allavgprice then '=' |when h.avgprice < h.allavgprice then '-' end |) |from hive4 h |""".stripMargin)
defmysqlExtract(spark: SparkSession, mysqlName: String, tempName: String): Unit = { val url = "jdbc:mysql://192.168.23.89/shtd_store" val driver = "com.mysql.jdbc.Driver" val user = "root" val password = "123456" spark.read.format("jdbc") .option("url", url) .option("driver", driver) .option("user", user) .option("password", password) .option("dbtable", mysqlName).load().createTempView(tempName) } } }
sql( """ |with t1 as ( |select cust_key, |cast(date_format(order_date,'yyyyMM') as int) as month, |sum(total_price) as total_price, |count(1) as total_order |from dwd.fact_orders |group by cust_key,cast(date_format(order_date,'yyyyMM') as int) |), |t2 as ( |select |a.cust_key, |concat(a.month,'_',b.month) as month, |a.total_price + b.total_price as total_price, |a.total_order + b.total_order as total_order |from t1 a |left join t1 b | on --判断连续两个月增长 |a.cust_key=b.cust_key |where |a.month + 1 = b.month |and |a.total_price < b.total_price) |select c.cust_key,c.name,month,total_price,total_order |from t2 |left join dwd.dim_customer c on c.cust_key=t2.cust_key |""".stripMargin).coalesce(50).createTempView("hiveOrders")